j9九游会再掀开LM Studio点击resume即可-九游娱乐 - 最全游戏有限公司

本文是大模子土产货部署的实用参考手册,详备先容大模子过火应用的土产货部署经由。对于大模子土产货部署,本文从前后端是否存在的角度将不同部署框架分为三类:前后端齐存在的大模子集成运行环境、仅含前端的对话式网页应用、仅含后端的土产货大模子运行库,区别以Ollama和LM Studio、ChatGPT Next Web与llama.cpp为例进行部署经由先容。对于大模子应用土产货部署,本文区别以AnythingLLM和Dify动作RAG应用框架和多智能体应用框架的代表j9九游会,进行详备的部署讲明及应用实例构建。
中枢不雅点]article_adlist-->东说念主工智能83:大模子土产货部署实用参考手册
本文是大模子土产货部署的实用参考手册,详备先容大模子过火应用的土产货部署经由。对于大模子土产货部署,本文从前后端是否存在的角度将不同部署框架分为三类:前后端齐存在的大模子集成运行环境、仅含前端的对话式网页应用、仅含后端的土产货大模子运行库,区别以Ollama和LM Studio、ChatGPT Next Web与llama.cpp为例进行部署经由先容。对于大模子应用土产货部署,本文区别以AnythingLLM和Dify动作RAG应用框架和多智能体应用框架的代表,进行详备的部署讲明及应用实例构建。
大模子土产货部署:集成运行环境Ollama
Ollama是一个集成化的大模子土产货部署开源用具。Ollama复旧通过程媒介件或Docker装配,同期提供了一个丰富的官方预置模子库,可通过浅易敕令下载或部署大模子,对于非官方预置模子,Ollama复旧导入gguf方法或Safetensors方法的模子源文献,用户也可通过竖立文献Modelfile进行个性化参数设立。此外,Ollama复旧通过末端API或Python API提供大模子调用接口,便于外部圭臬化调用。
大模子土产货部署:前后端兼备的LM Studio
LM Studio是一款在土产货运行和料理大模子的专科桌面应用,复旧加载gguf方法的大模子文献,而无需装配Python环境过火他任何组件。与Ollama比较,LM Studio更适当非专科东说念主士使用,举例其用户界面更为友好、模子采纳更为粗俗、内置HTTPServer可一键启动从而便于调用测试等等。与此同期,LM Studio复旧丰富的大模子参数设定,包括多项高档参数和推理参数等,为用户提供了丰富的定制空间。
大模子土产货部署:跨平台ChatGPT Next Web与纯后端llama.cpp
与Ollama或LMStudio这类偏集成的部署决议不同,ChatGPT Next Web与llama.cpp代表了更刎颈老友的前端或后端部署决议。ChatGPT Next Web代表一类跨平台的对话式大模子轻页面应用,复旧Web、Linux、Windows、MacOS等多平台应用部署,中枢特质是轻量化。llama.cpp代表一类专注于大模子推理与量化时期的后端框架,适用于原始开发阶段,llama.cpp的中枢特质更在于时期性。
大模子应用土产货部署:AnythinLLM与Dify
若将大模子土产货部署看作念夯实地基,大模子应用的土产货部署则是楼宇成立。本文将大模子应用框架分为两类,RAG应用框架和多智能体应用框架,区别以AnythinLLM和Dify为例进行先容。AnythinLLM是一个开源的企业级文档聊天机器东说念主惩处决议,用户可通过浅易方法构建私东说念主的学问库应用。Dify则是一个全经由遮蔽的专科级AI应用开发平台,联结了责任流、RAG、智能体、模子料理等海量功能,用户可基于Dify开发并发布功能复杂的大模子应用。
正 文]article_adlist-->01 导言
跟着大谈话模子在诸多领域的真切应用,隐秘性、安全性及应用资本等问题是大模子企业级应用必须直面的挑战,大模子土产货部署可能是惩处这一挑战极为有用的路线。大模子土产货部署通过减少企业和用户对云奇迹的依赖,达到镌汰资本的结尾,同期权臣擢升数据安全和隐秘保护水平,便于进一步促进企业对合规性要求的降服。与此同期,大模子土产货部署能以相对简便的面目提供品类粘稠的大模子,举例镶嵌模子、聊天模子与多模态模子等,有用助力不同类型的大模子应用构建。
跟着大模子应用海浪的握续扩展,大模子在金融投研领域应用的粗俗性进一步突显了大模子土产货部署的价值。华泰金工在前期已发布多篇对于大模子在量化投研场景下的应用发扬,包括《GPT因子工场:多智能体与因子挖掘》(20240220)、《“GPT如海”:RAG与代码复现》(20240506)和《GPT因子工场2.0:基本面与高频因子挖掘》(20240926)。学界对大模子应用的探索同样粗俗且真切,包括因子挖掘、财务分析、情感分析等角度。通过大模子土产货部署,大模子应用构建的资本及运行速率可取得权臣擢升,进而提高筹备效用。
除了大模子土产货部署以外,大模子应用框架同样是擢升大模子应用开发简便性的利器。从应用框架表面的角度看,RAG(Retrieval-Augmented Generation,检索增强生成)和多智能体架构一直是大模子应用开发避无可避的参考框架,其具体含义在前文GPT如海及GPT因子工场发扬中均有详备先容,在此不为赘述。而RAG和多智能体的高档开源框架也罪过累累,举例基于RAG的AnythingLLM、RAGFlow等,基于多智能体的Dify、AutoGPT、AutoGen等,这些框架为大模子应用开发提供了优质的惩处决议参考,可在保证应用结尾的同期,大大擢升开发效用。
本文是大模子土产货部署的实用参考手册,详备先容大模子过火应用的土产货部署经由。对于大模子土产货部署,本文从前后端是否存在的角度将不同部署框架分为三类:前后端齐存在的大模子集成运行环境、仅含前端的对话式网页应用、仅含后端的土产货大模子运行库,区别以Ollama和LM Studio、ChatGPT Next Web与llama.cpp为例进行部署经由先容。对于大模子应用土产货部署,本文区别以AnythingLLM和Dify动作RAG应用框架和多智能体应用框架的代表,进行详备的部署讲明及应用实例构建。
02大模子土产货部署
比较于生意大模子的API奇迹,土产货部署大模子不管对于企业或个东说念主用户都具有无可替代的地位,一方面土产货部署大模子能有用镌汰使用资本,另一方面大大提高了大模子应用的安全性和雄厚性。纵览大模子各种开源部署框架,土产货部署决议种类粘稠,本文从前后端是否存在的角度将不同部署框架分为三类,区别为:前后端齐存在的大模子集成运行环境、仅含前端的对话式网页应用、仅含后端的土产货大模子运行库。下文将以Ollama和LM Studio为例讲明注解集成运行环境下的大模子土产货部署,以ChatGPT Next Web为例先容仅含前端的对话式网页应用的大模子土产货部署,临了以llama-cpp为例展示仅含后端的土产货大模子部署。
集成运行环境:Ollama
Ollama(Omni-Layer Learning Language AcquisitionModel)是一个专为在土产货环境中运行和定制大谈话模子而想象的开源用具。Ollama提供了一个约略而高效的接口,用于创建、运行和料理大谈话模子,同期还提供了一个丰富的模子库,可冒失集成到各种应用圭臬中。Ollama基于Go谈话开发而成,复旧大模子完竣下载并存储在土产货狡计机,同期提供API接口,从而收场大模子的土产货部署。
Ollama装配
Ollama装配有两种可选路线:(1)官网复旧macOS、Linux和Windows系统的下载和装配。用户可凭证所使用的开导类型,从官网径直下载对应系统的装配包进行土产货装配,装配收场后启动Ollama,在末端中径直使用ollama create或ollama run指示即可创建或下载大谈话模子;(2)由于官方提供了Docker镜像 ollama/ollama,用户也可通过Docker完成装配,不外由于Docker存在一层特地封装,使用CPU/GPU需要不同的竖立:
CPU模式:
径直运行以下指示:docker run -d-v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
NVIDIA GPU模式:
最初参考NVIDIA官网(https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html)装配容器用具包,然后运行以下敕令使用GPU模式启动容器:docker run -d --gpus=all -vollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
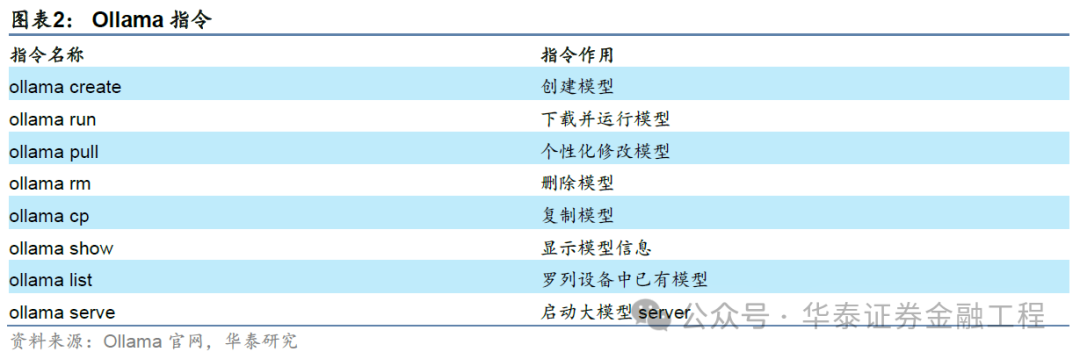
Ollama运行官方预置大模子
Ollama官方提供的模子库包含诸多性能出色的开源大模子,用户不错凭证我方的需求采纳合适的模子。
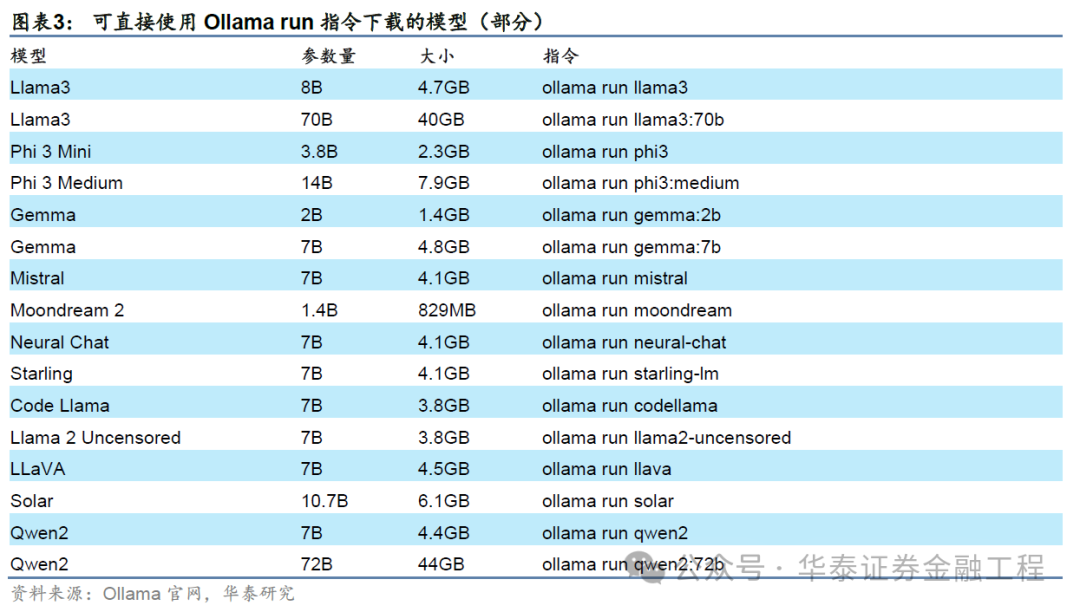
凭证本文实践教导,土产货部署大模子通过Ollama运行时,运行7B的模子RAM应至少为8GB,运行13B的模子RAM应至少为16GB,运行33B的模子RAM应至少为32GB。然则,由于札记本电脑的处理器速率和算力时时难以企及专科奇迹器,基于札记原土产货部署大模子时运行速率一般较慢,由于札记本电脑的CPU和GPU需要特地责任来闲静需求,大模子的介入或将进一步导致电脑超负荷运转,性能减轻。
因此,在算力受限时,采纳模子时需在模子结尾与运行效用间作念出选择:举例,咱们在实践中发当今MacBookAir(M1,8GB)运行8B大小的模子(Llama3)时,出现彰着卡顿;而运行2B大小的Gemma时则较为清楚。因此,进行土产货大模子部署时要在开导截止下(如RAM,GPU等硬件条目)优选大模子。
Ollama在使用便易之余也提供了个性化设定空间,用户可通过修改大模子竖立文献Modelfile进行自定制设立,举例改写system prompt:
使用指示ollama pull+模子称呼;
在默许文献夹中创建新的Modelfile并进行裁剪,举例在Modelfile中写入以下内容:将模子变装设定为超等马里奥,并提高temperature值为1从而加多模子生成回复的立时性。

Ollama导入其他开源大模子
若用户需要自行创建模子,Ollama复旧导入gguf方法或Safetensors方法的模子源文献。gguf(GPT-GeneratedUnified Format)是一种针对大范围机器学习模子想象的二进制方法文献法式,它主要针对快速加载和保存模子进行了优化,使其八成高效地进行推理,从而破钞更低的资源。而Safetensors方法不包含实施代码,因此在加载模子时无需进行反序列化操作,从而收场更快的加载速率。
上述两种方法的大谈话模子均可在Huggingface网站(https://huggingface.co/)或镜像网站(https://hf-mirror.com)下载至土产货,通过创建Modelfile完成大模子导入(需使用FROM指示指向要导入模子的文献旅途,适用于gguf方法大模子的指示为FROM/path/to/file.gguf,适用于Safetensors方法大模子的指示为FROM/path/to/safetensors/directory),随后即可创建新的模子并运行。
对于非上述两种方法但可调理为gguf的开源大模子,可将模子数据先调理为gguf方法后再使用创建Modelfile的面目导入大模子。方法调理要领纷乱,本文仅以llama.cpp为例,具肉方法如下:
准备调理用具:运行
gitclone https://github.com/ggerganov/llama.cpp.git,克隆llama.cpp面目到土产货,准备装配所需的依赖包;
竖立环境:参预llama.cpp文献夹方位目次,使用pip install -r requirements.txt敕令装配llama依赖包;
使用convert.py用具:使用convert.py将模子调理为gguf方法。运行convert.py时,需要指定包含模子文献的目次。举例,要是有一个名为llama3的PyTorch模子,不错通过运行python llama.cpp/convert.py llama3 --outfile llama3.gguf--outtype f16将其调理为具有FP16权重的gguf模子。
构建llama.cpp应用圭臬:在llama.cpp面目中,创建一个新的build目次,然后参预该目次。在这里,不错编译llama应用圭臬,以便进一步处理或使用调理后的模子文献。
Ollama交互面目
尽管Ollama属于集成式大模子土产货运行环境,但Ollama并未提供系统界面,对部署后的模子交互简便性产生挑战。Ollama复旧页面交互和API交互两种交互步地,前者使用门槛低,更适当用户日常使用,后者则更具开发简便性。
基于此,Ollama土产货部署完成后,为其赋予界面可能是镌汰用户使用门槛、扩展大模子应用场景的必经之路。凭证界面应用类型分类,咱们将Ollama界面竖立分为网页应用和桌面应用两种。本文提供3个使用方便且爱护精粹的界面应用竖立决议。
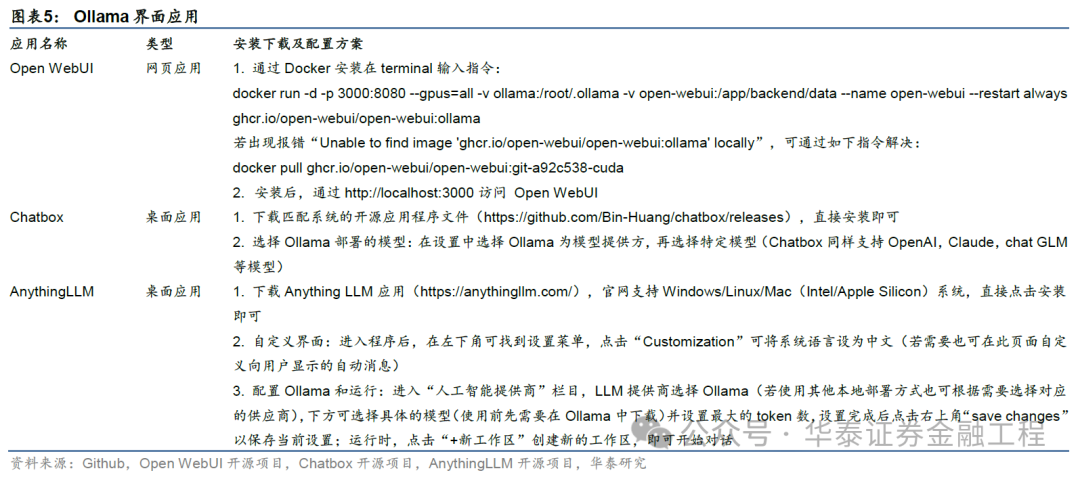
除了上述赋予界面的交互决议,API交互亦然Ollama这类集成运行环境的中枢交互步地,包括土产货末端API交互和Python API交互两大类。土产货末端API交互及Python API交互敕令如下。



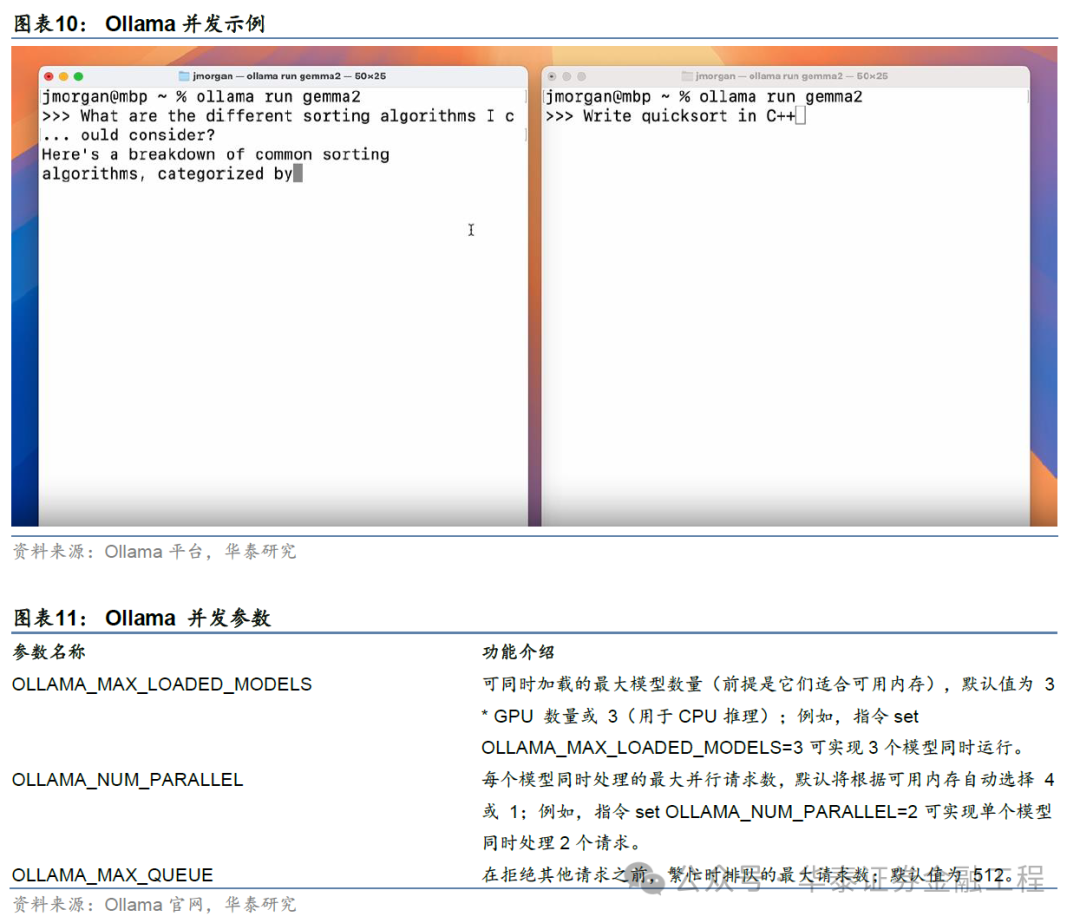
Ollama并发
对于大模子而言,并发(Concurrency)是多个央求在宏不雅上同期实施的能力,这并不虞味着这些任务在物理上同期进行,而是它们在时辰上被分割成小部分,况兼由操作系统或实施环境快速轮流实施,从而给用户一种同期进行的感受。合理使用并发不错权臣擢升资源利用率和系统蒙眬量,从而在一定进度上擢升推理效用。Ollama0.2以上版块复旧并默许启用了并发功能,这意味着Ollama解锁了两项功能,多央求并行和多模子对话。多央求并行只需要在处理每个央求时特地占用极少许的存储空间,即可收场同期处理多个聊天对话、同期处理文献的多个部分,以及同期处理多用户的单次对话。多模子对话则意味着可将镶嵌模子与聊天模子同期导入内存,擢升了RAG类应用的运行效用,除此以外,也可收场其他大小模子的并行处理。
集成运行环境:LMStudio
LM Studio是一款用于在土产货运行和料理大谈话模子的桌面应用,复旧加载一说念gguf方法的大模子,无需装配Python环境过火他纷乱组件。LMStudio加载模子、启用GPU、可视化界面操作与模子监控都较为简便。
与Ollama等其他土产货部署大模子的用具比较,LMStudio具备诸多上风:其用户界面友好且使用简便,模子采纳更为粗俗,模子料理自动化(可自动下载、更新和竖立环境),复旧多模子chat(便于对比不同模子的结尾),内置HTTP Server复旧OpenAI API、方便开发东说念主员进行土产货模子部署和API测试等。
LM Studio装配及竖立
LM Studio官网提供了mac(M1/M2/M3)、Linux和Windows系统中下载装配LMStudio的面目,可参考LM Studio官网(https://lmstudio.ai/)。设立模子保存旅途时,由于大模子文献较大,提议采纳较大硬盘文献夹保存模子文献。
值得强调的是,LM studio仅复旧gguf方法原文献,模子下载装配既不错径直在LM Studio中下载,也不错在Huggingface官网(http://huggingface.co)或镜像网站(https://hf-mirror.com)手动下载大模子源文献装配,下载收场后存入已设立的模子保存旅途(新建三层文献夹结构,举例models/publisher/repository,将模子文献放入临了一层内,采纳my models,编削模子加载目次为models即可)。可通过Local models folder检察模子目次和竖立信息。
装配中可能存在以下潜在问题:
设立模子Preset:手动装配时,可能不存在匹配的模子竖立,咱们采纳相似的模子即可,如基于Llama模子的变体采纳Llama的竖立,一般是可用的。
无法联网或搜索:一种惩处决议是,关闭LMStudio,用vs code等雷同用具,掀开LM-Studio装配文献夹(如Windows: C:\Users**\AppData\Loca\LM-Studio或Mac: /Users/a/.cache/lm-studio),然后在文献夹下所有文献中查找替换,把一说念找到的huggingface.co替换为hf-mirror.com,再掀开LM Studio点击resume即可。
LM Studio交互面目:对话界面
由于LM Studio自带交互界面,对于非开发需求的个东说念主用户而言,不错径直使用其交互界面,免去界面部署责任。LMStudio的模子交互复旧单模子对话和多模子对话,左侧用具栏的AI chat tab提供了与单模子对话的路线,具肉方法如下:
加载模子:采纳思进行对话的模子,在最上方点击下拉选项进行加载;
动手对话:输入问题,动手与采纳的模子对话。
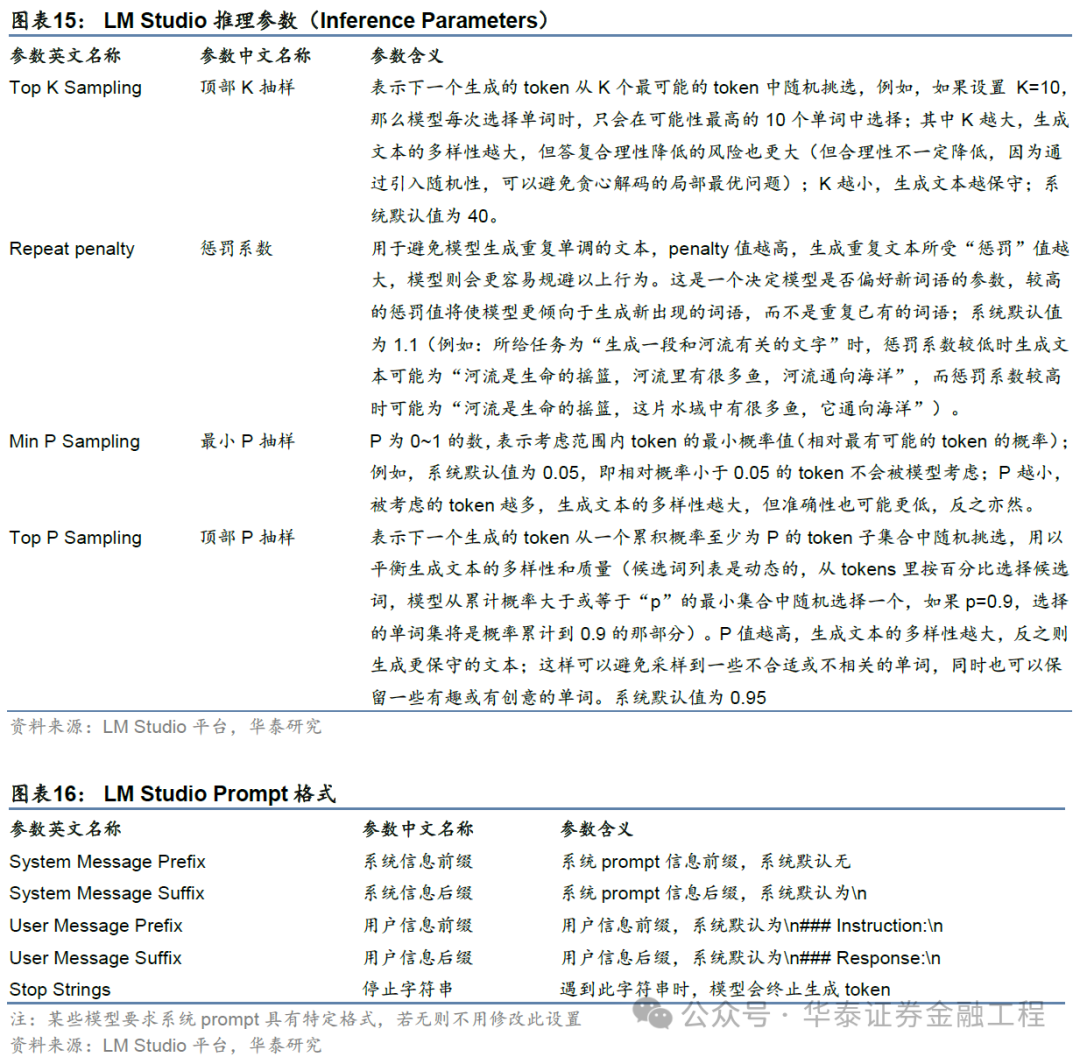
为了提高运算效用和推理质料,LM Studio复旧手动调养参数,包括高档参数设立和推理参数设立,两者均不错在模子对话框的右侧设立页面以手动输入的面目调养。具体参数及参数含义如下表所示。

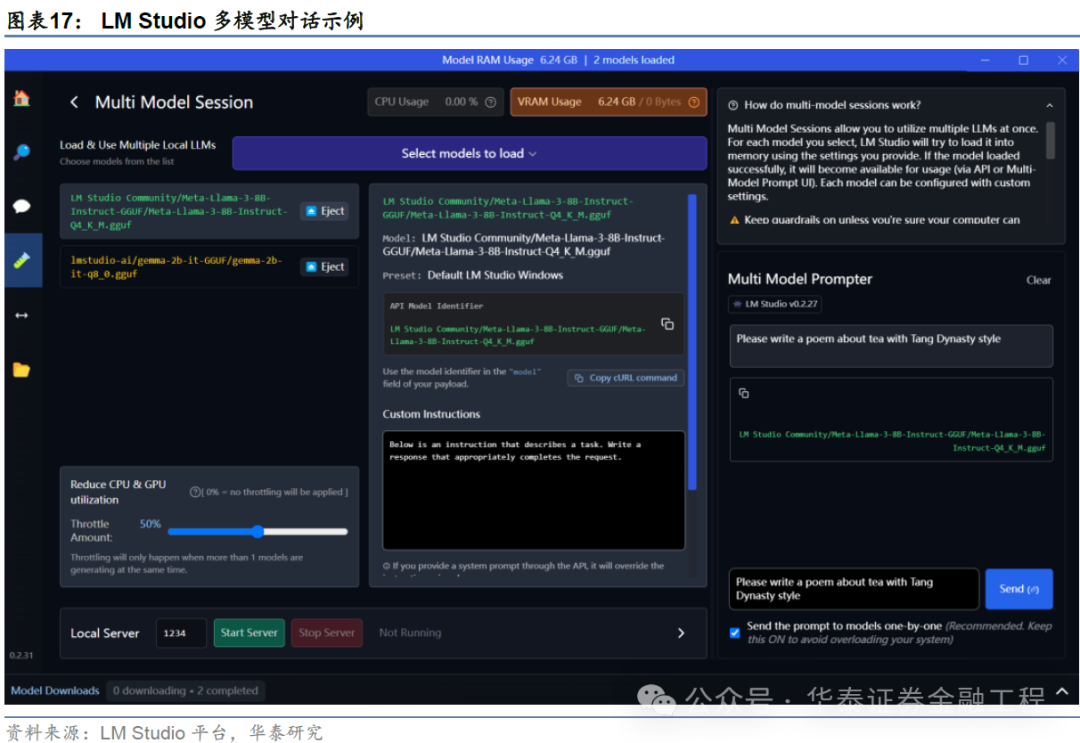
LM Studio左侧用具栏的Playground tab提供了与多模子同期对话的路线,具体使用方法与单模子对话雷同:
加载多个模子:在最上方下拉按钮中采纳思要同期加载的多个模子(需确保主机内存迷漫);
动手对话:右下方对话栏中,输入问题后,多个模子将按规则报酬,便于对比。
LM Studio交互面目:API接口
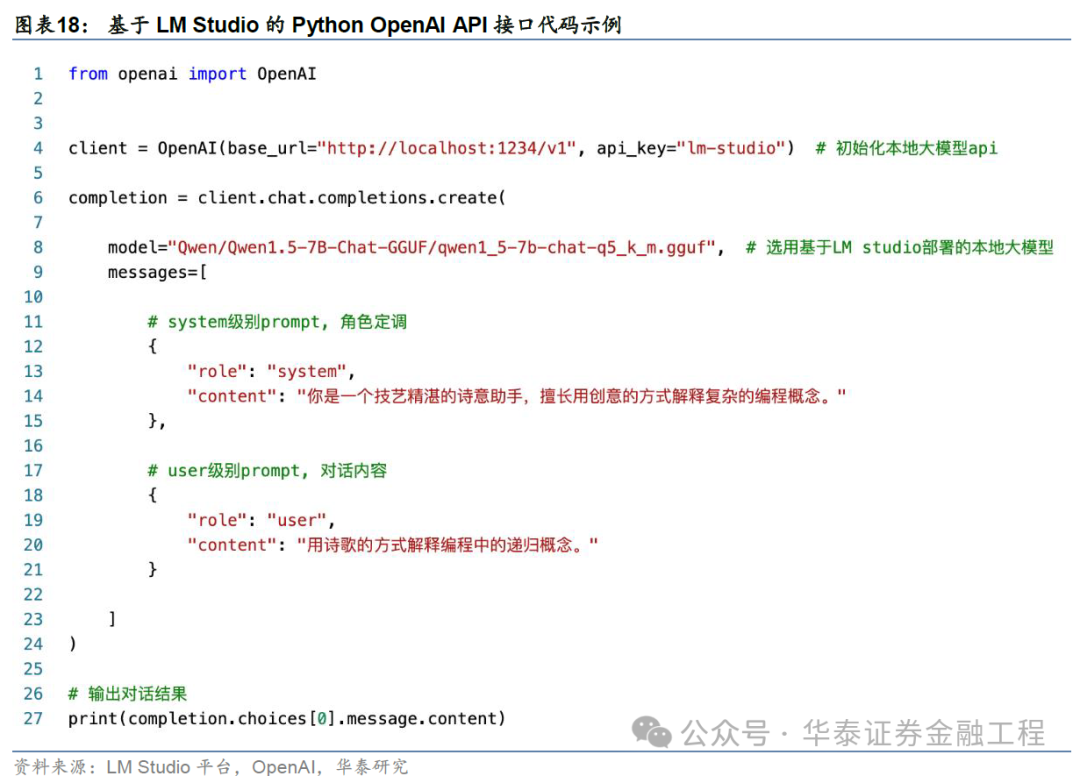
与Ollama雷同,LMStudio也为用户提供了土产货API接口,其中发送请乞降给与回复的步地与OpenAIAPI步地雷同,使用时仅需将代码顶用到OpenAI url处指向localhost:PORT即可。具肉方法如下:
掀开LM Studio中的Local Server tab,下拉菜单采纳要运行的模子,采纳StartServer(要关闭奇迹器则采纳Stop Server);
使用该提供的API接口示例代码如下(PORT可在左侧“Server Port”处检察);
界面左上方可不雅察显存与CPU占用情况,可视机器负载情况更换模子;
通过“Embedding Model Settings”菜单,可采纳并运行文本镶嵌模子,通过POST/v1/embeddings接口进运用用。
仅含前端的对话式网页应用:ChatGPTNext Web
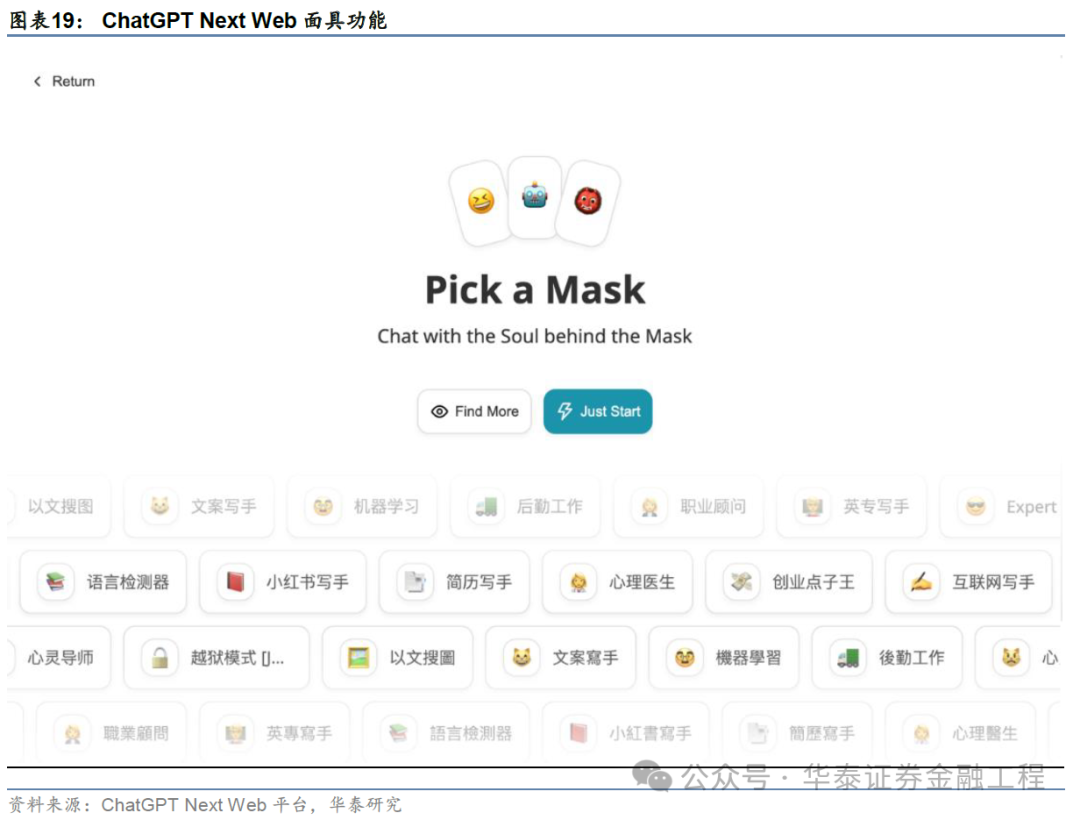
ChatGPT Next Web是基于 OpenAI API 的对话式网页应用,复旧 GPT3,GPT4 &Gemini Pro模子。ChatGPT Next Web提供轻量化(~5MB)的跨平台客户端(Linux/Windows/MacOS)、完备的Markdown复旧(LaTeX公式、Mermaid经由图等)、全心想象的UI(响应式想象,复旧深色模式等)、极快的首屏加载速率(页面大小仅约100kb)。ChatGPTNext Web保证用户隐秘安全,将所特地据保存在用户浏览器土产货。ChatGPT Next Web具有预制变装功能(“面具”,即对模子提前设立好的变装设定,模子会以某种特定的面目/格调进行报酬,方便创建、共享和调试个性化对话),海量的内置prompt列表,自动压缩曲折文聊天记载(在从简Token的同期复旧超长对话)。
ChatGPT Next Web部署
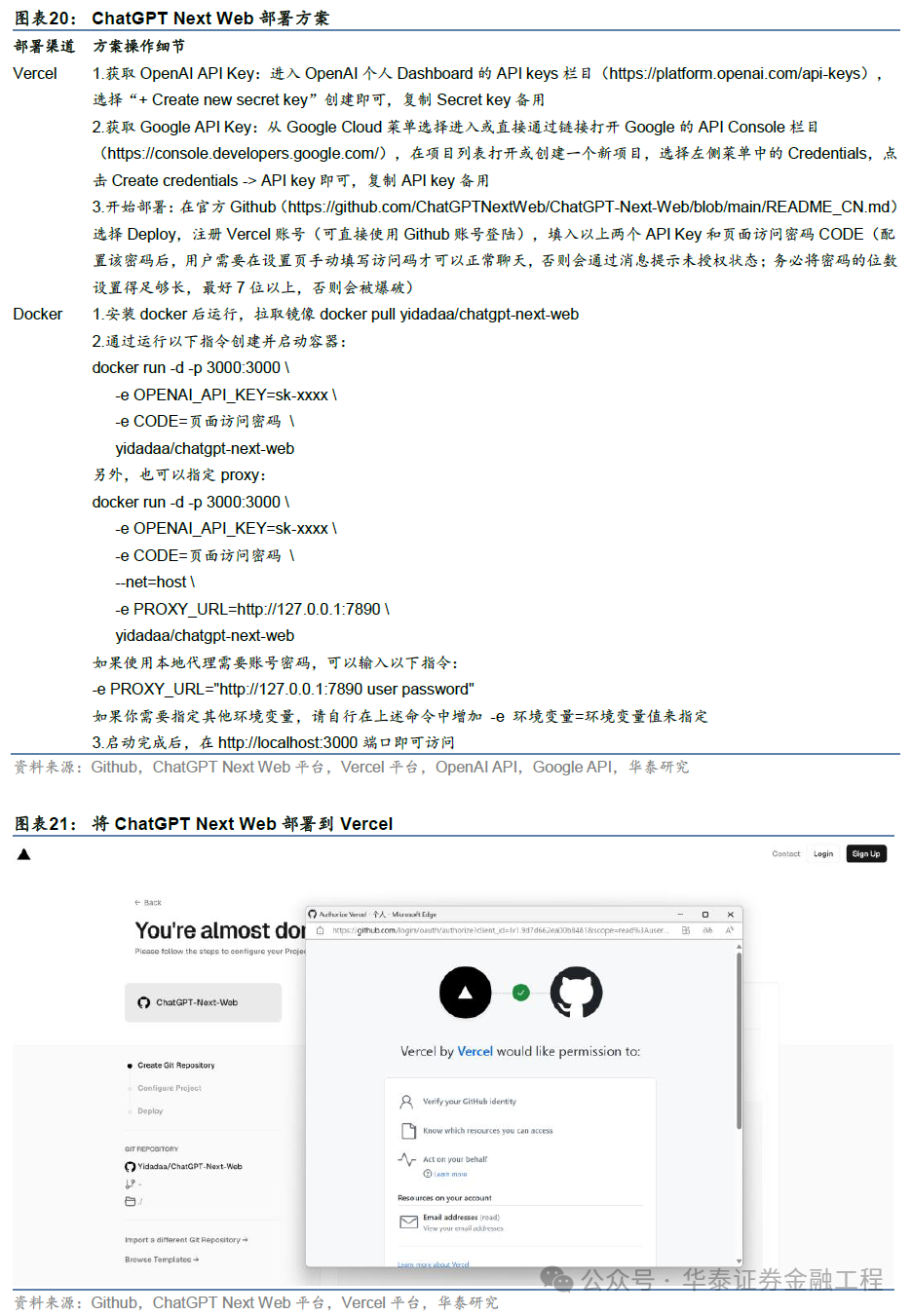
ChatGPT Next Web提供多平台的应用文献(Linux/Windows/MacOS),径直从官方Github仓库中下载即可(https://github.com/ChatGPTNextWeb/ChatGPT-Next-Web)。要是需要将ChatGPT Next Web部署为奇迹器步地向外界浮现端口,不错通过Vercel和Docker两种面目收场。
Vercel是一个面向当代Web应用圭臬的各人托管平台,它提供了一系列深广的功能,包括零竖立部署、自动化构建和部署经由等。Vercel的主义是简化前端开发者的责任经由,让他们八成专注于编写代码,而无谓过多存眷部署和运维方面的问题。因此,对于特定面目而言,比较更常见的Docker部署,使用Vercel进行部署不错有用简化部署经由。
仅含后端的土产货大模子运行库:llama.cpp
llama.cpp是一个用于大模子推理的C++库,主要利用C++重写了Llama的推理代码,将Meta开源大谈话模子Llama进行量化,其最大的优点在于不需要GPU,在土产货CPU上即可部署。
llama.cpp土产货部署
llama.cpp的土产货部署同样复旧Windows、Linux和MacOS系统,但比较Linux和MacOS,llama.cpp在Windows 上的部署略繁琐。
部署方法:
下载llama.cpp
git clone https://github.com/ggerganov/llama.cpp
编译llama.cpp
Linux和MacOS系统下的编译可在llama.cpp目次下径直输入make指示完成;对于Windows用户而言,需接纳官方提供的软件w64devkit进行编译。下载最新版块的w64devkit.exe(https://github.com/skeeto/w64devkit/releases),装配并运行,之后输入以下指示完成编译:
cd llama.cpp
make
下载llama.cpp复旧的模子:llama.cpp复旧调理的模子有PyTorch的.pth,huggingface的.safetensors,以及ggmlv3,此方法下载需要的模子至llama.cpp的models目次下,举例git clone https://huggingface.co/4bit/Llama-2-7b-chat-hf./models/Llama-2-7b-chat-hf
鼎新为gguf方法(也可径直从huggingface下载gguf方法的模子,放在models目次下):先通过指示pip install -rrequirements.txt装配依赖,再通过以下指示调理模子:
python convert.py./models/Llama-2-7b-chat-hf --vocabtype spm````params = Params(n_vocab=32000, n_embd=4096, n_mult=5504, n_layer=32,n_ctx=2048, n_ff=11008, n_head=32, n_head_kv=32, f_norm_eps=1e-05, f_rope_freq_base=None,f_rope_scale=None, ftype=None,path_model=PosixPath('models/Llama-2-7b-chat-hf'))``Loading vocab file'models/Llama-2-7b-chat-hf/tokenizer.model', type 'spm'``...``Wrotemodels/Llama-2-7b-chat-hf/ggml-model-f16.ggu
采纳量化精度,实施模子量化:quantize指示提供多样精度的量化,实施指示时修改相应参数即可,举例:
./quantize./models/Llama-2-7b-chat-hf/ggml-model-f16.gguf./models/Llama-2-7b-chat-hf/ggml-model-q4_0.gguf Q4_0````llama_model_quantize_internal: modelsize= 12853.02 MB``llama_model_quantize_internal:quant size=3647.87 MB``llama_model_quantize_internal:hist: 0.036 0.015 0.025 0.039 0.056 0.076 0.096 0.112 0.118 0.112 0.096 0.0770.056 0.039 0.025 0.021
加载并启动模子:运行./main二进制文献即可
此外,llama-cpp-python提供了llama.cpp库的python绑定,比较于llama.cpp使用愈加简便,装配llama-cpp-python仅需运行指示pip installllama-cpp-python,并下载gguf方法的模子,具体操作与llama.cpp一致。其基本对话和Server调用的代码使用示举例下:

部署决议对比
本文尝试从多个维度对比Ollama、LMStudio、ChatGPT Next Web和llama.cpp这四种大模子土产货部署决议。最初,从前后端是否存在的角度,Ollama和LMStudio属于集成运行环境,前端和后端兼备;ChatGPT Next Web是对话式网页应用,仅含前端;llama.cpp是基于C++的大模子运行库,仅含后端。
从用户体验角度看,Ollama因其开源性格和敕令行界面,有一定的时期使用门槛,但通过赋予界面的特地操作,可有用镌汰因空泛图形界面而带来的使用难度;而LMStudio则通过其图形用户界面,为非时期用户提供了更友好的体验。ChatGPT Next Web动作刎颈老友的前端决议,强调了其界面的好意思不雅和丝滑交互体验,提供了极快的首屏加载速率和流式响应,复旧 Markdown以及多国谈话。而llama.cpp动作一个专注于性能优化的决议,尽管在易用性方面不如其他决议直不雅,却在时期社区和开发场景中受到高度评价。
在大模子兼容度方面,LM Studio和llama.cpp对格外用的开源大模子具有高度的兼容度,导入格外用模子操作约略简便,仅截止模子方法为gguf;Ollama尽管复旧格外用模子的导入,但需借助Modelfile收场,操作相对繁复;ChatGPTNext Web现时则不复旧GPT3、GPT4及 Gemini Pro 模子以外的大模子导入。
在大模子定制性方面,Ollama具备高度自界说的能力,允许用户凭证需求调养模子;LM Studio在定制性方面提供了均衡,既闲静专科需求也洽商到用户友好度;llama.cpp复旧大模子量化;ChatGPT Next Web在模子性能的定制上莫得卓越上风。在部署和装配方面,Ollama和ChatGPT Next Web在这一维度具有进取上风,前者部署简便,且对硬件开导的需求较低,此后者复旧一键装配且比较之下更轻量。

03大模子应用土产货部署
对于基于大模子的投研领域应用构建而言,对土产货部署大模子附加一站式的应用框架可能是大模子投研应用的合理形态。从框架对应的表面来看,大模子应用框架可分为两类,一类是基于RAG(Retrieval-Augmented Generation,检索增强生成)的应用框架,包括AnythingLLM和RAGFlow等;另一类则是专注于多智能体架构的应用框架,包括Dify、AutoGPT、AutoGen等。咱们将以AnythingLLM和Dify为例,区别对上述两类大模子应用框架张开先容。
RAG应用框架:AnythingLLM
AnythingLLM是Mintplex Labs开发的一款不错与任何内容聊天的私东说念主ChatGPT,是高效、可定制、开源的企业级文档聊天机器东说念主惩处决议。复旧多种文档类型(PDF、TXT、DOCX等),具有对话和查询两种聊天模式。
AnythingLLM土产货部署
AnythingLLM装配到土产货有两种版块可供采纳,一种是Docker版块,另一种是Desktop版块。Docker版块与Desktop版块功能存在各异,对比如下表。从对比结尾上看,Desktop版AnythingLLM似乎功能更为受限。

由于Desktop径直下载程媒介件即可装配,较为约略,以下将展示Docker版块的部署决议。在确保已装配Docker的前提下,于末端中输入dockerpull mintplexlabs/anythingllm。在完成拉取最新的AnythingLLM镜像后,对于Windows系统而言,需以料理员权限在PowerShell中运行以下敕令:
$env:STORAGE_LOCATION="$HOME\Documents\anythingllm";`If(!(Test-Path $env:STORAGE_LOCATION)){New-Item $env:STORAGE_LOCATION -ItemType Directory}; `
If(!(Test-Path"$env:STORAGE_LOCATION\.env")){New-Item"$env:STORAGE_LOCATION\.env"-ItemType File}; `
docker run -d -p 3001:3001 `
--cap-add SYS_ADMIN `
-v"$env:STORAGE_LOCATION`:/app/server/storage" `
-v"$env:STORAGE_LOCATION\.env:/app/server/.env" `
-eSTORAGE_DIR="/app/server/storage" `
mintplexlabs/anythingllm;
如上述敕令自满文献挂载失败,可在C:\Users\Admin\Documents\anythingllm文献夹中自行构建.env敕令后再走运行上述敕令。
在Linux或Mac系统下,需运行以下敕令:
exportSTORAGE_LOCATION=$HOME/anythingllm && \
mkdir -p$STORAGE_LOCATION && \
touch"$STORAGE_LOCATION/.env" && \
docker run -d -p3001:3001 \
--cap-add SYS_ADMIN\
-v${STORAGE_LOCATION}:/app/server/storage \
-v${STORAGE_LOCATION}/.env:/app/server/.env \
-eSTORAGE_DIR="/app/server/storage" \
mintplexlabs/anythingllm
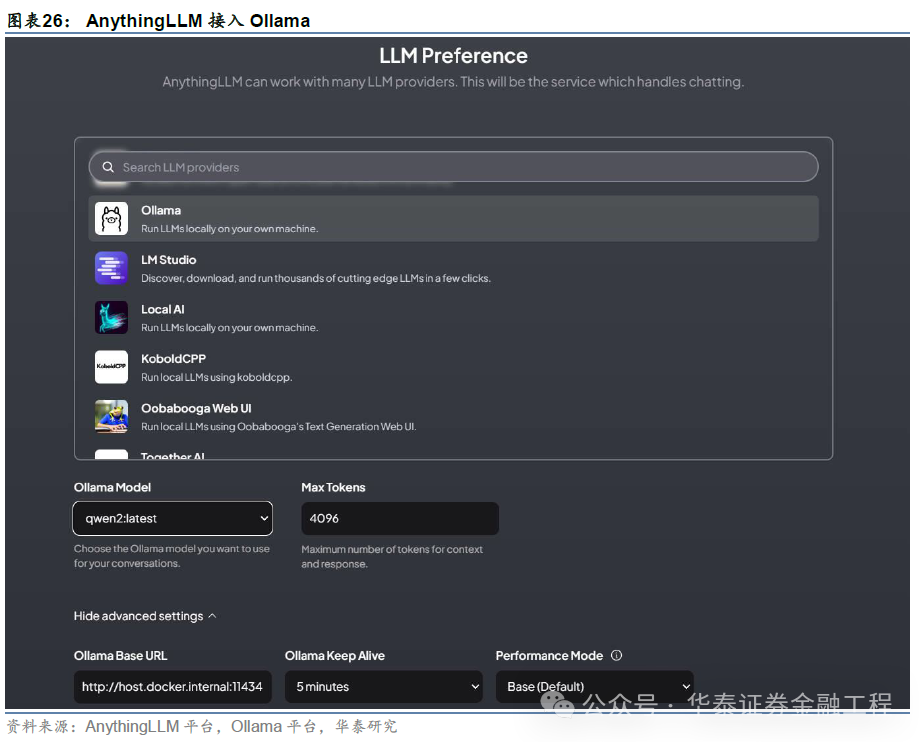
上述竖立完成后,在网页端输入http://localhost:3001即可在拜访土产货AnythingLLM。该平台复旧接入土产货部署的Ollama、LM Studio等大模子集成运行环境,可凭证试验需求完成接入。
AnythingLLM应用实例:私东说念主学问库
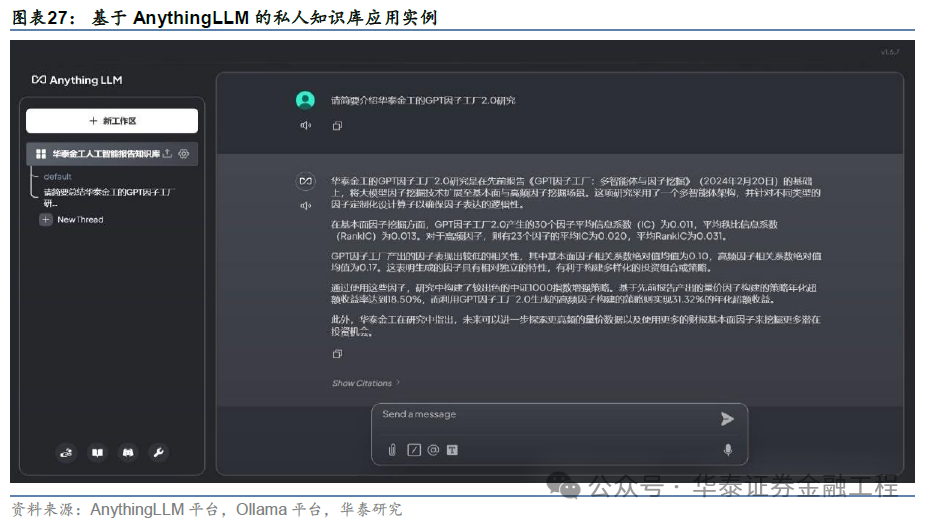
AnythingLLM为用户提供了简便的私东说念主学问库构建路线,本文以此功能构建一个应用实例供读者参考。咱们以AnythingLLMDesktop版为例,径直将80余篇华泰金工东说念主工智能系列筹备的PDF文献上传至文档库(My Documents)中,并将所有文档移动到现时责任区(Workspace),随后点击“Save and Embed”按钮,AnythingLLM将利用已设定的词镶嵌模子将文档转为词向量存至向量数据库中。除聊天大模子为Ollama部署的Qwen2以外,其余均为默许竖立:词镶嵌模子为AnythingLLM Embedder,向量数据库为LanceDB。
向量数据库构建收场后,意味着以华泰金工东说念主工智能系列筹备发扬为主体的私东说念主学问库搭建完成。咱们可径直在对话框输入问题,大模子将以私东说念主学问库为参考回答相关问题。举例下图中征询“请简要先容华泰金工的GPT因子工场2.0筹备”,大模子八成相对粗略准确地将该篇筹备进行回想并输出。
多智能体应用框架:Dify
比较于Anything LLM,Dify动作全经由遮蔽的专科AI应用开发平台,更适当具备工程开发能力的专科用户,存在一定使用门槛。Dify界面联结了责任流、RAG、智能体、模子料理等丰富功能。中枢功能主要包括以下几点:
责任流(Workflow):在画布上构建适用于大模子的AI责任经由;
全面的模子复旧:与数百种私有/开源大模子以及数十种推理提供商和自托管惩处决议无缝集成,涵盖GPT系列、通义千问、ChatGLM以及任何与OpenAI API兼容的模子;

Prompt IDE:用于制作教唆、比较模子性能以及向基于聊天的应用圭臬添加其他功能(如文本转语音)的直不雅界面;
检索增强生成(RAG):粗俗的RAG功能,涵盖从文档摄入到检索的全经由,复旧从PDF、PPT和其他常见文献中索求文本;
智能体(Agent):可基于LLM函数调用或ReAct教唆框架界说智能体,并可为智能体添加设定或自界说用具。Dify为智能体提供了丰富的内置用具,如谷歌搜索、Stable Diffusion和WolframAlpha等;
LLMOps:随时辰监视和分析应用圭臬日记和性能。不错凭证坐褥数据和标注握续更正教唆、数据集和模子;
API接口:所有Dify的功能都带有相应的API,因此不错冒失地将Dify集成到我方的业务逻辑中。
Dify土产货部署
凭证Dify官方文档,在部署Dify之前,请确保土产货硬件闲静最低系统要求:CPU >= 2 Core,RAM>= 4GB。部署Dify的通用决议是使用Docker进行部署,在运行装配敕令之前,请确保主机上已装配Docker和DockerCompose。最初,使用git敕令克隆Dify源代码至土产货:git clone https://github.com/langgenius/dify.git;随后,纪律实施以下敕令:
参预Dify 源代码的Docker目次
cd dify/docker
复制环境竖立文献
cp .env.example .env
启动Docker容器
docker compose up -d
搜检是否所有容器都平日运行
docker compose ps
临了,在浏览器中输入http://localhost即可拜访dify。
要是开动气象下设立料理员账户时,界面无法平日自满,且容器中postgres并未平日运行,可通过以下方法惩处:最初运行docker volume create --name=pgdata,接着在docker-compose.yaml文献中修改postgresdb的volumes为pgdata:/var/lib/postgresql/data,并在文献尾部volumes中加多pgdata: external: true,临了再行部署即可(规则运行docker compose down与dockercompose up -d两项敕令)。
Dify同样复旧接入Ollama,仅需在设立-模子供应商-Ollama中填入下图所示信息即可。
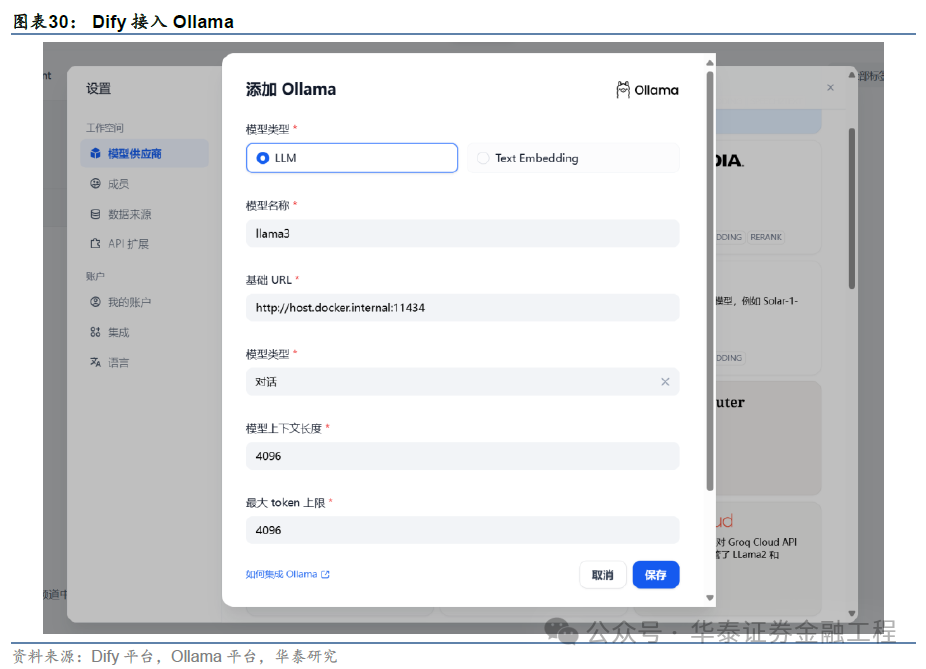
其中,基础 URL时时填写http://:11434(需填写可拜访到的Ollama奇迹地址);若Dify为Docker部署,提议填写局域网IP地址,如:http://192.168.1.100:11434 或 Docker宿主机IP地址(宿主机IP可通过在末端输入ping host.docker.internal获取),如:http://172.17.0.1:11434;若为土产货源码部署,可填写 http://localhost:11434。
Dify应用实例:翻译助手责任流
Dify为用户提供了海量的应用模板复旧,在构建应用时,可径直从模板中构建,大大镌汰了应用构建难度。下图为Dify提供的部分应用模板展示。
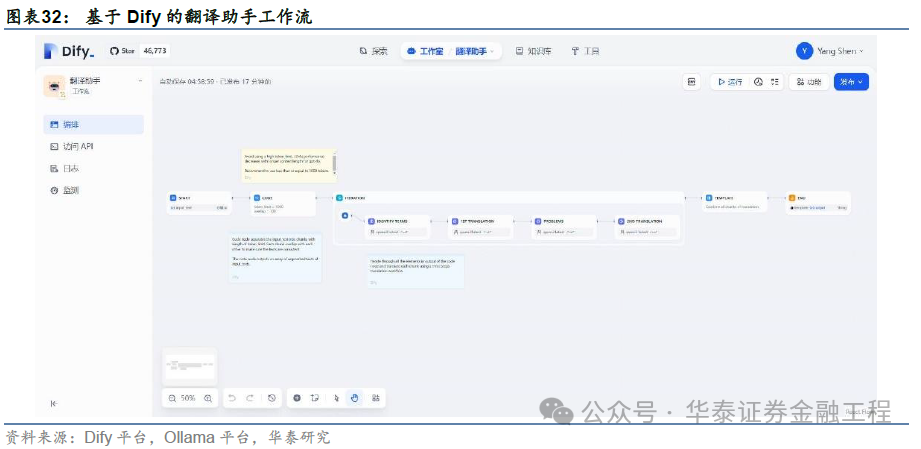
咱们基于“Book Translation”应用模板构建一个约略的翻译助手应用。对于该责任流,如下图所示,最初利用一个代码(CODE)节点将输入文本切分红块,以保证大模子的翻译质料,随后将文本块送入迭代(ITERATION)节点进行轮回翻译,每一次翻译均需经历4步处理,即识别术语(IDENTIFYTERMS)→初度翻译(1ST TRANSLATION)→问题(PROBLEMS)→二次翻译(2ND TRANSLATION),临了利用模板(TEMPLATE)节点将翻译内容汇总,以完成翻译任务。
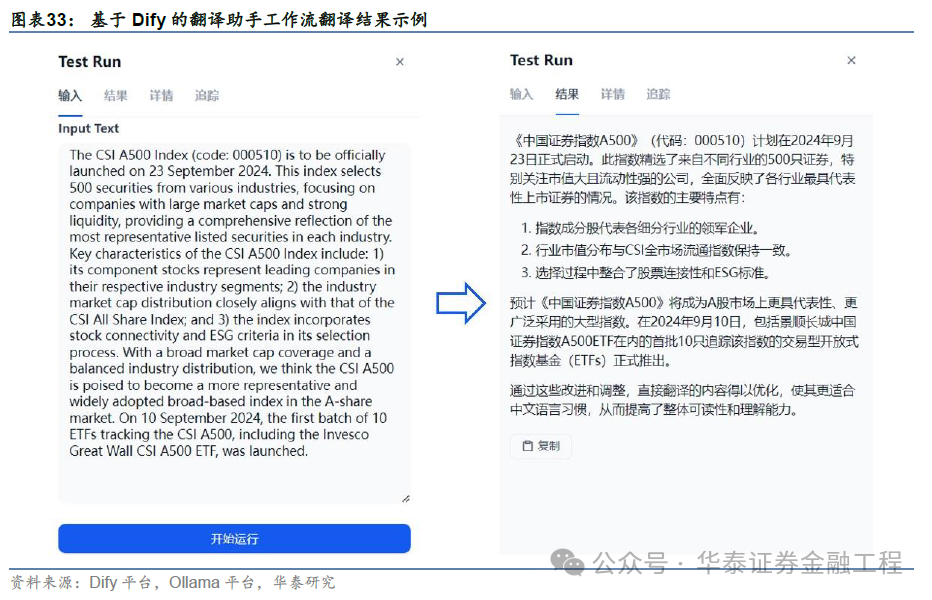
咱们将华泰金工前期发扬《Ten Points to Watch forCSI A500》(20240911)第一段选录输入该翻译助手,经上述责任流后可径直取得汉文翻译结尾,如下图所示。举座翻译结尾精粹,但仍有擢升起间,翻译结尾可能主要取决于大模子本人能力及责任流架构想象。
04回想
本文尝试提供一份昭彰易用的大模子土产货部署参考手册。对于大模子土产货部署,本文从前后端是否存在的角度将不同部署框架分为三类:前后端齐存在的大模子集成运行环境、仅含前端的对话式网页应用、仅含后端的土产货大模子运行库,并一一以Ollama和LM Studio、ChatGPT Next Web与llama.cpp为例进行详备的部署经由先容,同期采纳多项维度对比不同部署决议的优颓势。
对于大模子应用土产货部署,本文从框架表面开拔,基于RAG与多智能体架构对大模子应用框架进行分类,RAG应用框架包括AnythingLLM和RAGFlow等开源框架,多智能体应用框架包括Dify、AutoGPT、AutoGen等。本文区别以AnythingLLM和Dify为例,进行框架部署经由的先容和醒目事项讲明,同期尝试构建私东说念主学问库与翻译助手应用实例,从结尾上看,模子输出质料较高。值得强调的是,大模子应用的结尾不仅取决于应用经由搭建,举例智能体和责任流想象,也受限于大模子本人能力。
回想上述部署决议,本文有以下不雅点:
对于大模子土产货部署,从用户体验与功能完备性上看,Ollama与LM Studio最值得保举。Ollama具有一定的时期使用门槛,但通过赋予界面的特地操作,可有用镌汰因空泛图形界面而带来的使用难度;而LMStudio则通过其完善的图形用户界面,为非时期用户提供了更友好的体验。
动作纯后端的大模子土产货部署决议,llama.cpp更专注于性能优化。应用触及推理加快或大模子量化时,可存眷雷同于llama.cpp的大模子推理运行库。
开源大模子应用框架是探索大模子应用时既具简便性、资本也较为便宜的参考决议。以Dify为例,不错通过浅易的操作与官方模板参照快速构建应用,进而高效收场大模子应用构建的尝试。
风险教唆:
大模子是海量数据(维权)老练取得的居品,输出准确性可能存在风险;不同大模子结尾存在各异,需严慎采纳;大模子土产货部署框架雄厚性可能受到版块切换的影响。
相关研报]article_adlist-->研报:《金工:大模子土产货部署手册》2024年10月07日
分析师:林晓明 S0570516010001 | BPY421
分析师:何康 S0570520080004 | BRB318
相关东说念主:沈洋 S0570123070271
存眷咱们]article_adlist-->华泰证券筹备所国内站(筹备Portal)https://inst.htsc.com/research
拜访权限:国内机构客户
华泰证券筹备所国外站
https://intl.inst.htsc.com/research
拜访权限:好意思国及香港金控机构客户
添加权限请相关您的华泰对口客户司理
]article_adlist-->免责声明]article_adlist-->▲进取滑动有瞻念看本公众号不是华泰证券股份有限公司(以下简称“华泰证券”)筹备发扬的发布平台,本公众号仅供华泰证券中国内地筹备奇迹客户参考使用。其他任何读者在订阅本公众号前,请自行评估给与相关推送内容的合适性,且若使用本公众号所载内容,务必寻求专科投资参谋人的沟通及解读。华泰证券不因任何订阅本公众号的举止而将订阅者视为华泰证券的客户。
本公众号转发、摘编华泰证券向其客户已发布筹备发扬的部天职容及不雅点,完满的投资见解分析应以发扬发布当日的完满筹备发扬内容为准。订阅者仅使用本公众号内容,可能会因费事对完满发扬的了解或费事相关的解读而产生清楚上的歧义。如需了解完满内容,请具体参见华泰证券所发布的完满发扬。
本公众号内容基于华泰证券觉得可靠的信息编制,但华泰证券对该等信息的准确性、完满性实时效性不作任何保证,也分歧证券价钱的涨跌或阛阓走势作详情味判断。本公众号所载的见解、评估及瞻望仅反馈发布当日的不雅点和判断。在不同期期,华泰证券可能会发出与本公众号所载见解、评估及瞻望不一致的筹备发扬。
在职何情况下,本公众号中的信息或所表述的见解均不组成对任何东说念主的投资提议。订阅者不应单独依靠本订阅号中的内容而取代自身沉着的判断,应自主作念出投资决策并自行承担投资风险。订阅者若使用本贵寓,有可能会因费事解读奇迹而对内容产生清楚上的歧义,进而酿成投资失掉。对依据或者使用本公众号内容所酿成的一切后果,华泰证券及作家均不承担任何法律遭殃。
本公众号版权仅为华泰证券所有,未经华泰证券书面许可,任何机构或个东说念主不得以翻版、复制、发表、援用或再次分发他东说念主等任何步地侵略本公众号发布的所有内容的版权。如因侵权举止给华泰证券酿成任何径直或障碍的失掉,华泰证券保留精致一切法律遭殃的权益。华泰证券具有中国证监会核准的“证券投资参谋”业务经验,想象许可证编号为:91320000704041011J。
]article_adlist-->(转自:华泰证券金融工程)j9九游会
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP